CNN神經網路實作應用
影像辨示模型
辨識手寫數字
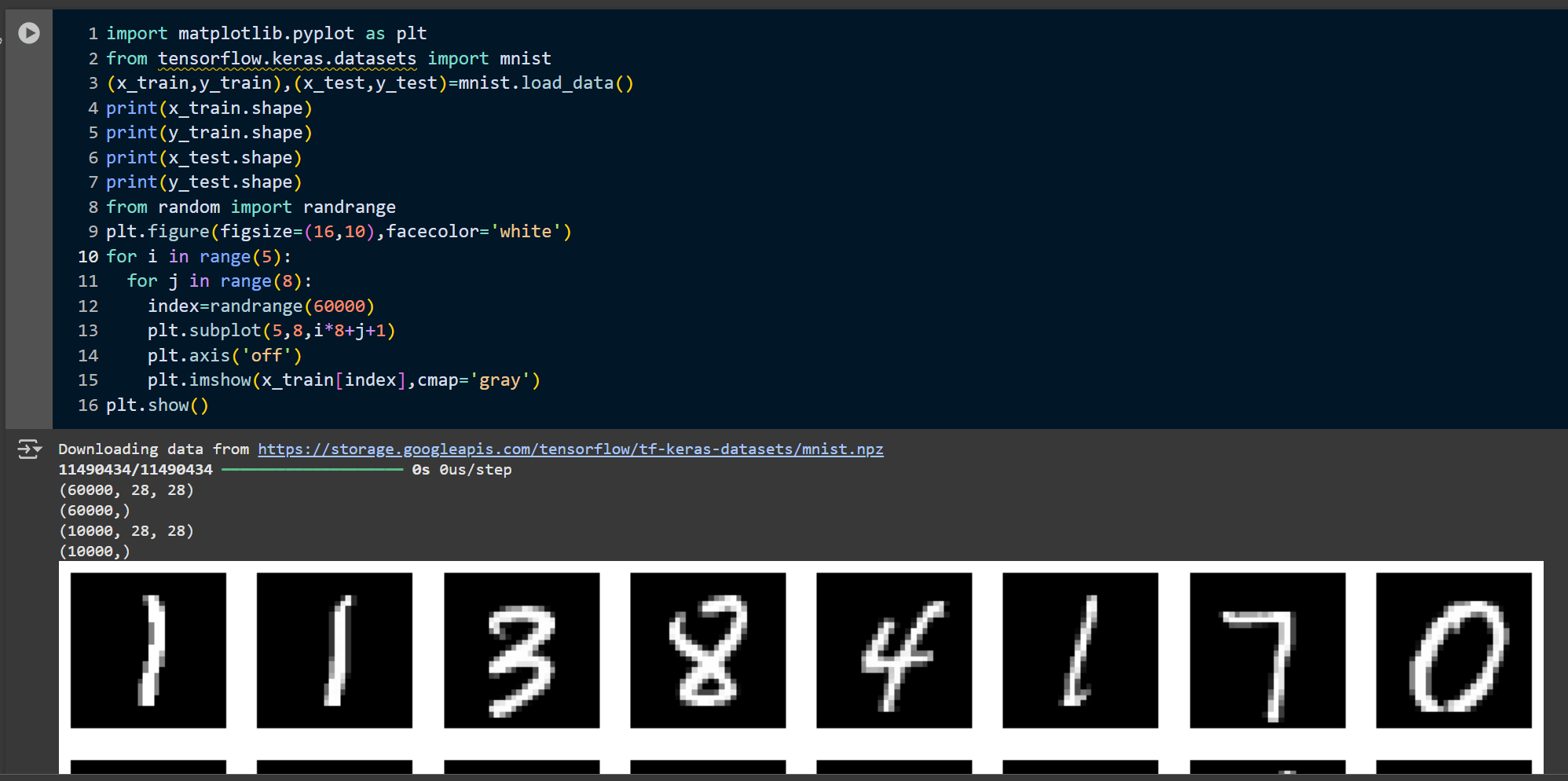
資料集:MNIST手寫數字資料集
特徵:像素值、圖像大小
標籤:數字0-9
資料量:60,000張訓練圖像,10,000張測試圖像
影象大小:28x28像素
評估:準確率、混淆矩陣
訓練資料集圖示:
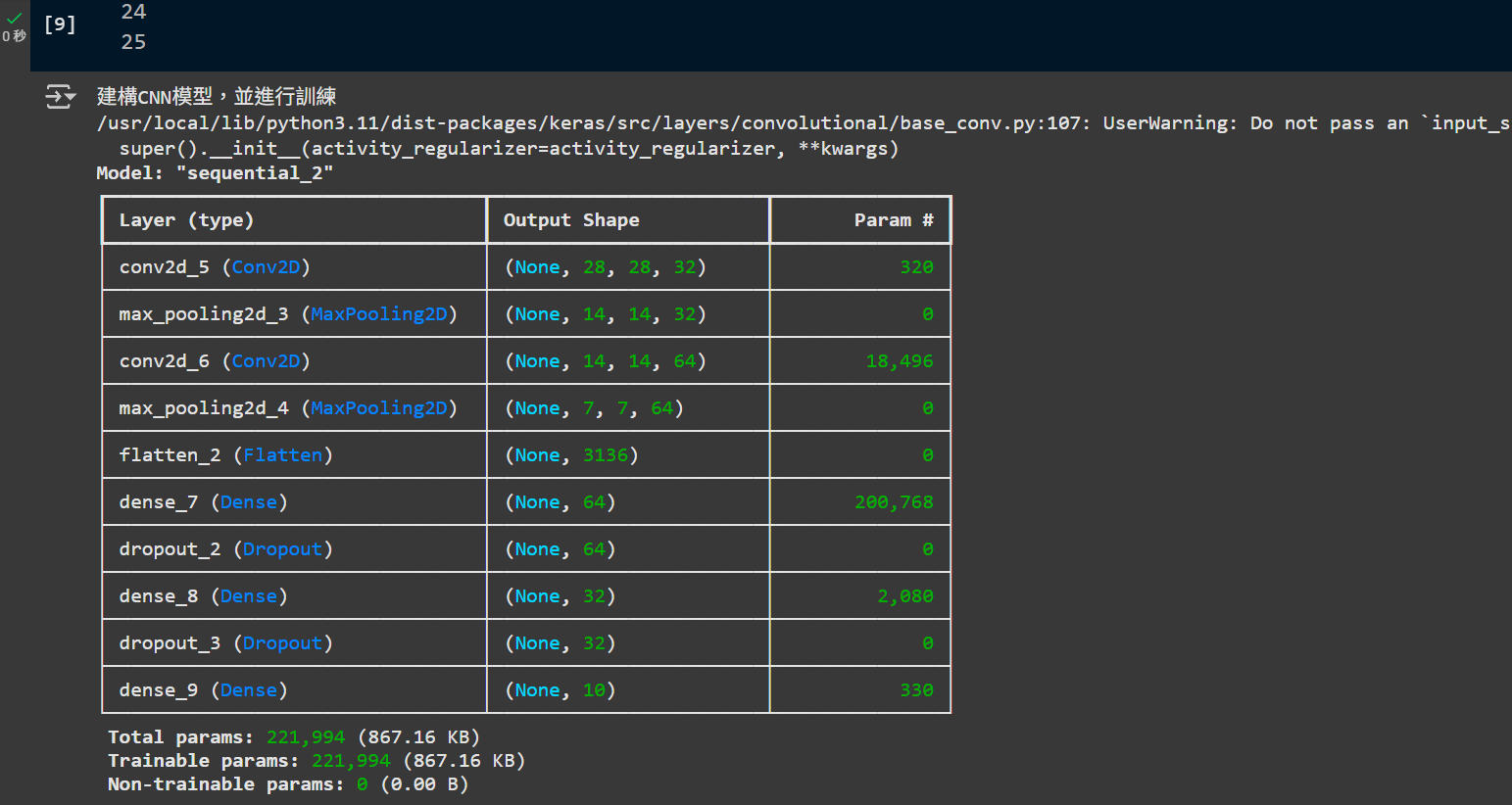
神經網路架構圖示:
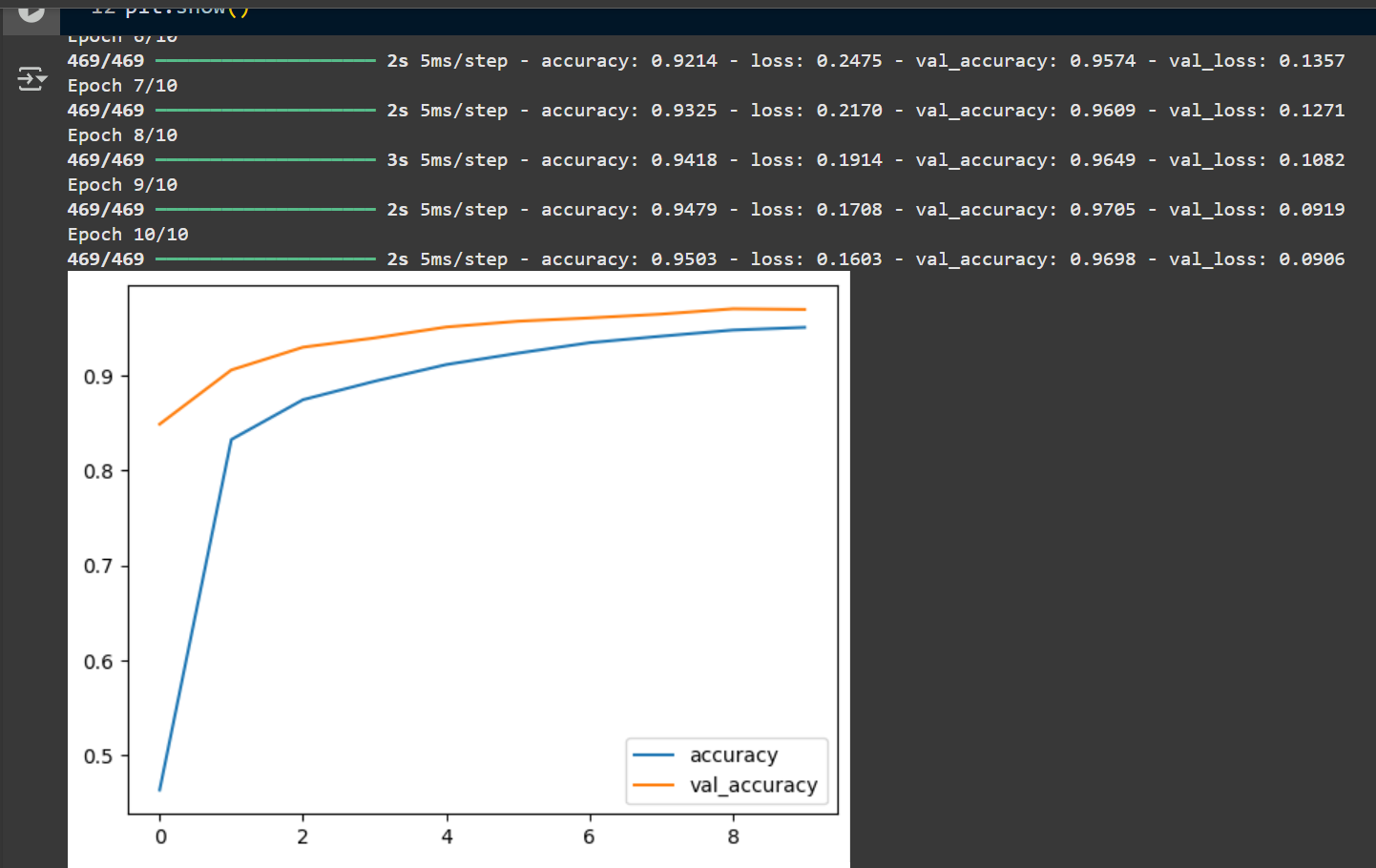
訓練成果圖示:
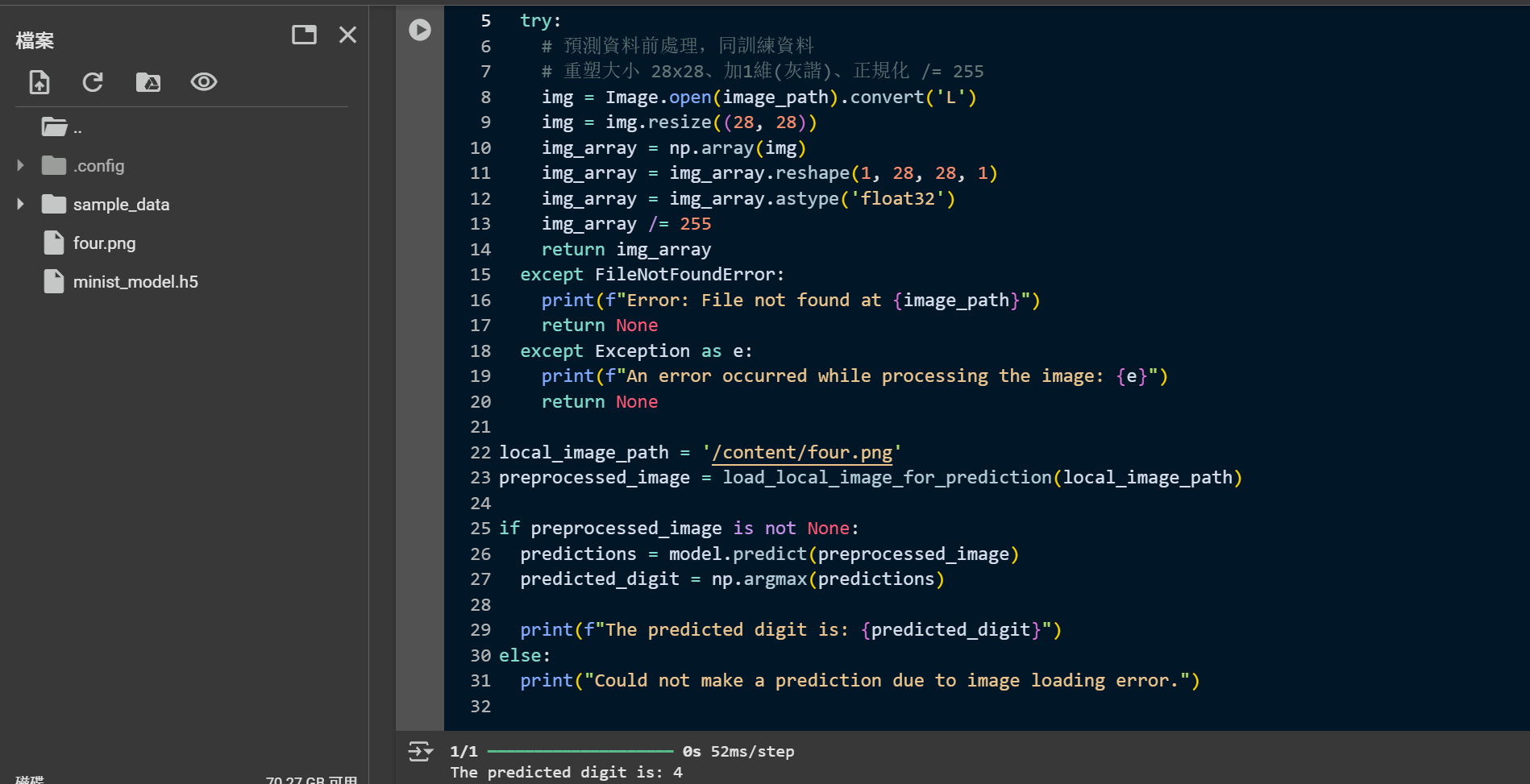
預測結果圖示:
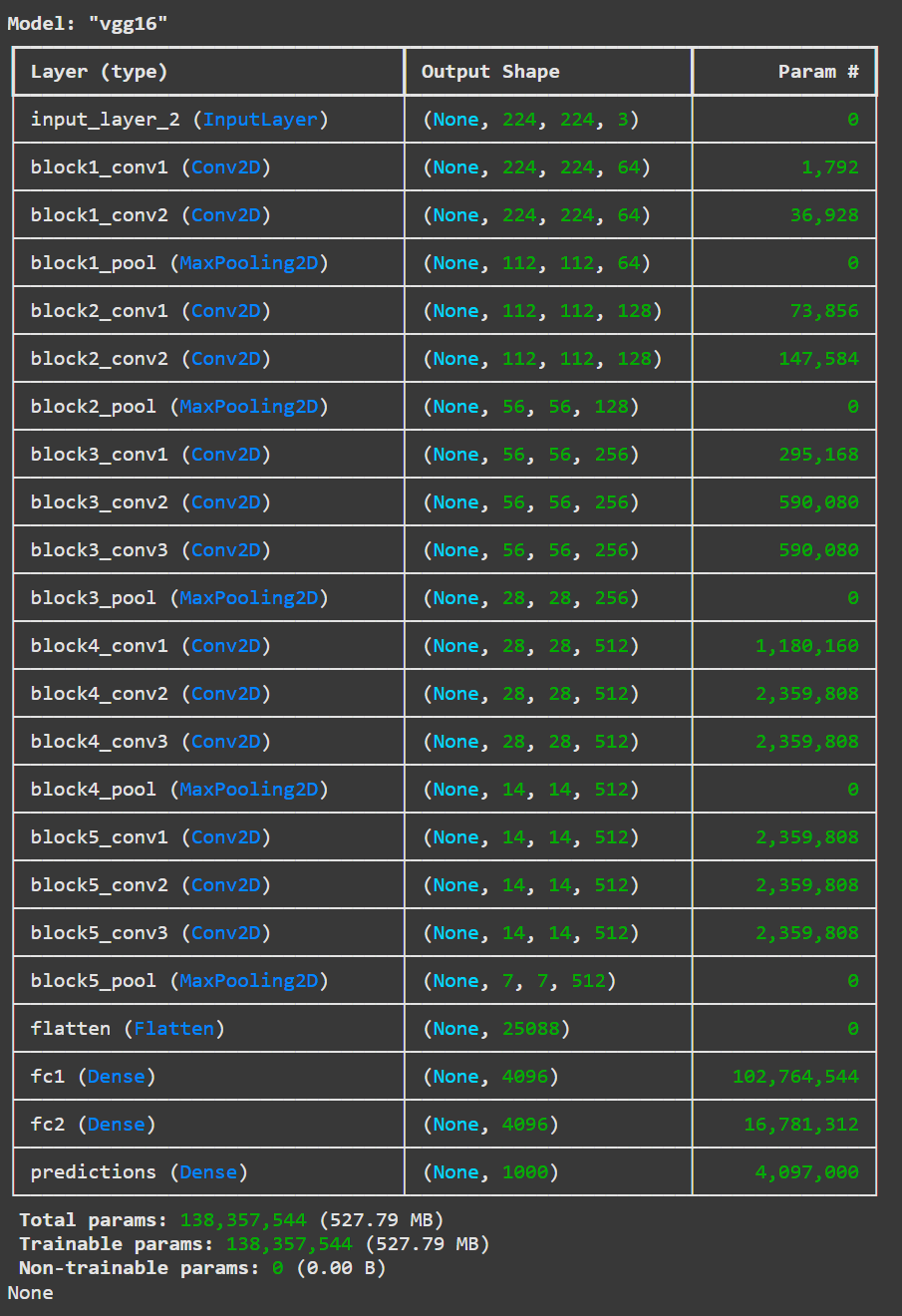
VGG16模型
使用現成模型預測
預模型介紹:VGG16是一種深度卷積神經網路,具有16層權重。可提供辨識1000種物體的能力。
模型輸入:224x224像素的RGB圖像
模型輸出:1000個類別的概率分佈
資料集:ImageNet資料集
神經網路架構圖示:
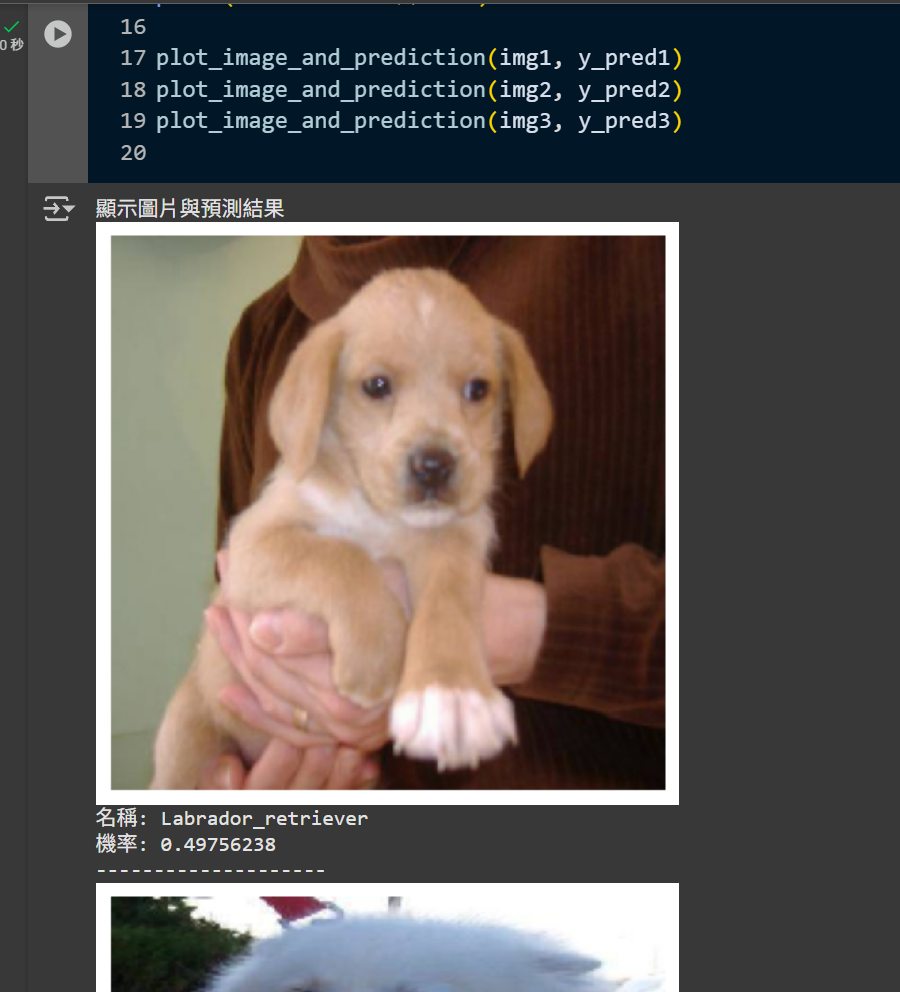
圖片預處理:將圖像調整為224x224像素,並進行標準化處理,如下流程範例程式碼:
import tensorflow.keras.preprocessing.image as image
# 載入圖片
img1 = image.load_img('y_pre.jpg', target_size=(224,224))
# 轉為numpy陣列
img1 = image.img_to_array(img1)
# 增加一個維度
img1 = np.expand_dims(img1, axis=0)
# 查看圖片形狀
print(img1.shape) # (1, 224, 224, 3)
# 對圖片陣列進行 VGG16 模型所需的預處理
img1 = vgg16.preprocess_input(img1)
# 進行預測
y_pred1 = model.predict(img1)
# 取得預測結果
y_pred1 = np.argmax(y_pred1, axis=1)
# 解析結果
tuple1 = vgg16.decode_predictions(y_pred1, top=1)[0]
for i in range(len(tuple1)):
print('名稱:', tuple1[i][1])
print('機率:', tuple1[i][2])
模型的限制:
僅能辨識ImageNet資料集中的1000種物體,對於其他類別的物體可能無法正確預測。
如果在工業生產、醫學影像、產品檢測等領域需要辨識特定類別的物體,則需要進行模型微調或轉移學習。
轉移學習:可以使用VGG16模型的特徵提取能力,將其應用於新的資料集上。
預訓練模型轉移學習 Transfer Learning
訓練目標:使用VGG16進行圖像分類任務,通過轉移學習來適應新的數據集。
資料:自訂資料集
特徵:圖像特徵
標籤:自訂標籤
評估:準確率、混淆矩陣
使用時機:
- 凍結預模型底層權重,替換或添加新的輸出層
- 預訓練模型的底層可以作為一個強大的特徵提取器,而無需重新學習這些通用特徵
模型微調 Fine-tuning
- 替換或添加新的輸出層,並像遷移學習一樣先訓練這些層
- 選擇性地解凍預訓練模型的頂部(或中間)層,甚至整個模型
- 在新的任務資料集上,以非常小的學習率繼續訓練解凍的層和新的輸出層。學習率之所以小,是為了避免破壞預訓練模型已經學到的良好特徵,而是進行微小的調整
- 計算成本比轉移學習高得多
實作心得
在本次實作中,我們使用了VGG16模型進行圖像分類任務。
通過轉移學習,我們能夠利用預訓練模型的特徵提取能力,並在自訂資料集上進行微調。
這樣的做法不僅提高了模型的準確率,還大大縮短了訓練時間。
未來,我們可以嘗試其他預訓練模型,如ResNet或Inception,以進一步提升性能。
開發訓練一個新的模型需要大量的計算資源和時間,而使用預訓練模型可以大大減少這些需求。
此外,轉移學習還能夠在小數據集上達到良好的效果,這對於許多實際應用場景非常有用。
不同領域的預模型合適性選擇
工業產品異常偵測
- ResNet 系列 (ResNet50, ResNet101等): 極為常用且效果好。由於異常偵測通常依賴於精細的紋理和局部特徵,ResNet 的深層結構和殘差連接能有效提取這些特徵。
- EfficientNet 系列 (EfficientNetB0-B7): 這些模型在精度和效率之間取得了極佳的平衡。如果需要部署到邊緣設備或計算資源有限的環境,EfficientNet 是很好的選擇,可以根據所需的模型大小選擇不同版本的 B。
- 物件偵測模型 (例如 YOLOv8n/s, Faster R-CNN): 如果異常表現為特定位置的「新物件」或「缺失物件」,或者需要精確定位異常區域,那麼物件偵測模型會更合適。你可以將正常模式下的產品組件視為一個個物件,偵測到不屬於這些物件的區域就是異常。
醫學影像
- ResNet 系列 (ResNet50, ResNet101等): 在醫學影像分類、分割(作為骨幹網路)和檢測中廣泛使用。其強大的特徵提取能力對識別病變模式至關重要。
- DenseNet 系列 (DenseNet121, DenseNet169等): 每個層級都直接連接到所有後續層級,促進了特徵重用,這對於醫學影像中複雜且細微的特徵提取非常有利,特別是對於小型病灶的識別。
- EfficientNet 系列: 在兼顧精度和計算效率方面表現出色,對於資源有限或需要快速推斷的醫療應用(如移動設備輔助診斷)非常有用。
- 物件偵測模型 (例如 YOLOv8n/s/m, Faster R-CNN, Mask R-CNN): 如果任務是定位和識別影像中的特定病灶(如腫瘤、結節),或進行實例分割(精確勾勒病灶邊界),YOLOv8 或 Mask R-CNN 等模型是首選。
生物種類辨識
- ResNet 系列 / Inception 系列 / EfficientNet 系列: 這些都是強大的通用圖像分類模型,非常適合進行生物種類的分類。ImageNet 預訓練的權重已經包含了豐富的紋理、形狀、顏色等視覺特徵,這些對於識別物種的外觀特徵非常有用。
- Vision Transformers (ViT) / Swin Transformers: 這些基於 Transformer 架構的模型在大型視覺任務上顯示出強大的性能,尤其是在數據量較大或特徵複雜的物種識別任務中,可能比傳統 CNN 表現更好。但它們通常需要更多的計算資源和更大的數據集來充分發揮潛力。
- MobileNet 系列 (MobileNetV2, MobileNetV3): 如果需要在移動設備或嵌入式設備上部署物種識別應用(如野外自動識別系統),輕量級的 MobileNet 系列是極佳選擇,它們在保持合理精度的同時實現了極高的效率。
- 物件偵測模型 (例如 YOLOv8): 如果任務是從複雜背景中識別和計數多個物種個體(例如,監測影像中的動物數量、識別照片中的多種植物),YOLOv8 就非常適合。