回歸模型實作應用
LinearRegression模型
Ridge / Lasso 模型
ElasticNET模型
LinearRegression模型通常有共線性問題,這會導致模型不穩定。為了解決這個問題,可以使用正則化技術,如 Ridge、Lasso 和 ElasticNET。這些技術可以幫助減少模型的複雜度,從而提高預測的準確性。
PolynomialFeatures模型
多項式回歸
不是一個獨立的預測模型,而是一種 特徵工程技術
超參數:degree (多項式的次數)
使用時機:資料集維度不高、非線性且可以用多項式曲線近似時
限制:特徵爆炸(特徵數量會呈指數級增長)、容易過度擬合、多重共線性、對噪音敏感
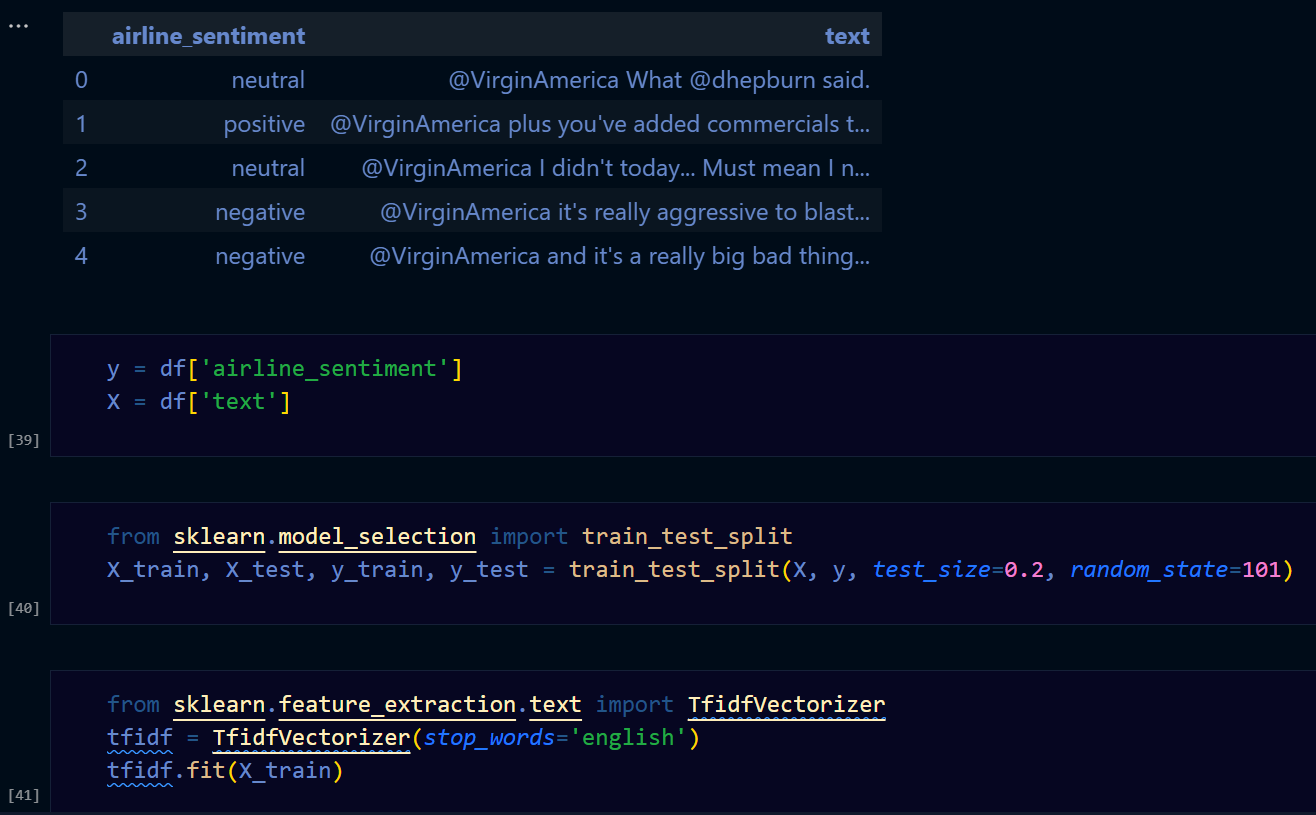
評估:均方誤差 MSE、R 平方值 R-squared
DecisionTreeRegressor模型
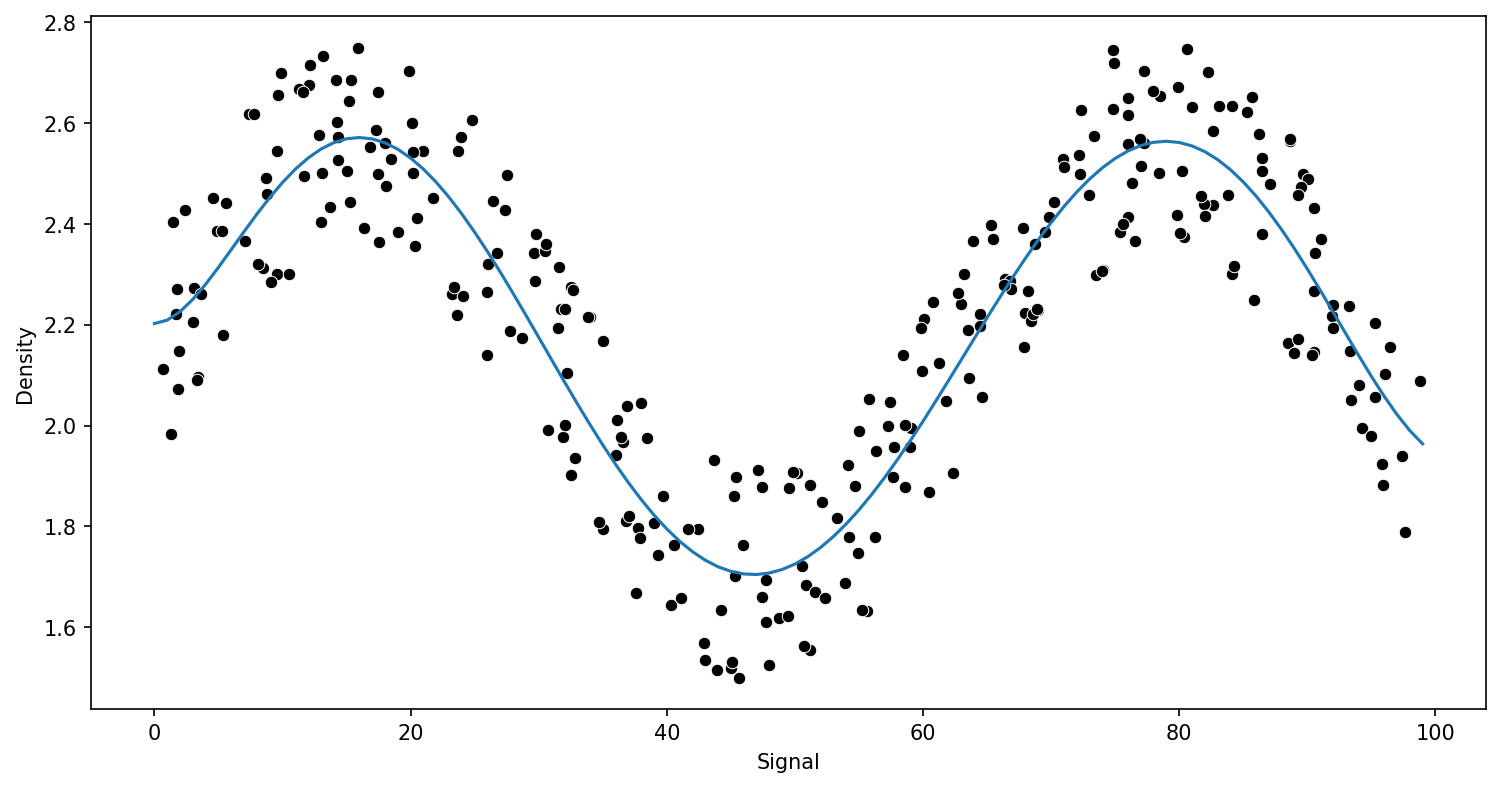
決策樹回歸
超參數:max_depth、min_samples_split
資料:非線性關係,且特徵之間的交互作用複雜
使用時機:資料量大、特徵維度高
限制:單一決策樹非常容易過度擬合訓練資料、不穩定性
評估:均方誤差 MSE、R 平方值 R-squared
RandomForestRegressor模型
隨機森林回歸
超參數:n_estimators、max_depth、min_samples_split
使用時機:需要高預測精度的迴歸任務、資料量大、特徵維度高、資料包含噪音或缺失值、對過度擬合問題比較敏感的情況
限制:計算成本高、記憶體消耗大、可解釋性較差、不適用於超高維稀疏資料
評估:均方誤差 MSE、R 平方值 R-squared
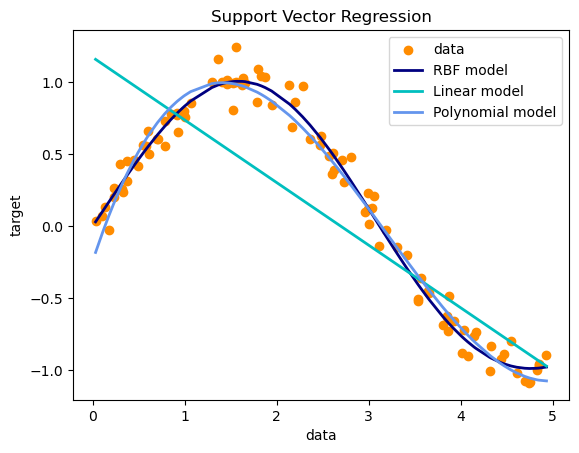
SVR模型
支持向量回歸
kernel:線性、RBF、Polynomial
超參數:C、kernel、gamma
使用時機:資料難以分離、需要高維度特徵、希望模型具有良好的泛化能力。
資料:非線性資料
限制:計算成本高、超參數選擇敏感、可解釋性差、不適用於超大型資料集
評估:均方誤差 MSE、R 平方值 R-squared
PolynomialFeatures、DecisionTreeRegressor、RandomForestRegressor、SVR的適性選擇:
- 資料量不大,需要捕捉非線性關係且對模型可解釋性要求高,可以從 DecisionTreeRegressor 開始,但要注意過擬合問題
- 對預測精度要求更高,且資料量適中到大,RandomForestRegressor 通常是一個非常強大且robust的選擇
- 在實際應用中,通常會嘗試多種模型,並透過交叉驗證 (Cross-Validation) 和網格搜索 (Grid Search) 等方法來選擇最佳模型和調整超參數,以達到最佳性能
XGBRegressor模型
極致梯度提升回歸
資料:非線性資料相當合適 超參數:booster、n_jobs、random_state、n_estimators、learning_rate、max_depth、min_child_weight、gamma、subsample等 使用時機:
- 數值型資料:對於連續型和離散型數值資料(如年齡、收入、溫度),XGBRegressor 表現優異
- 類別型資料:雖然 XGBoost 本身是基於樹的模型,可以直接處理數值型特徵,但對於類別型特徵,通常需要進行 One-Hot Encoding 或 Label Encoding 等預處理轉換為數值型
- 複雜的非線性關係資料:如果資料中的特徵與目標變量之間存在非線性關係,或者特徵之間存在複雜的交互作用,XGBRegressor 由於其基於決策樹的特性,能夠很好地捕捉這些複雜模式
- 資料量大且特徵維度高:能夠高效地處理大型數據集,甚至可以處理無法完全載入內存的數據;大數據應使用LightGBM
- 高維度特徵的資料表現良好,因為其具有內建的特徵選擇能力
- 存在缺失值的資料:其內建了對缺失值的處理機制,無需額外進行缺失值填充
- 需要高準確度且重視模型效能的場景:對預測準確性要求很高的實際應用中,XGBoost 經常是首選模型,因為它通常能達到領先的預測性能
LightGBM模型
光梯度提升機回歸
- 使用時機:大數據(~千萬筆數據集)適用,訓練速度極快;對訓練速度有嚴格要求,或者你的硬體資源有限時
- max_depth: 一個關鍵超參數,應相應設定其值以避免過度擬合
- num_leaves: 由於 LightGBM 逐葉生長,因此該值必須小於 2^(max_depth),以避免過度擬合的情況
- 具有大量類別型特徵的資料集:其內建的類別型特徵處理能力簡化了預處理流程
- 需要直接處理類別型特徵時:LightGBM 內建了對類別型特徵的優化處理,無需進行 One-Hot Encoding,這簡化了預處理步驟並提高了效率
- 缺點:LightGBM 在小資料集上更容易過擬合
實作範例程式碼📖
CatBoost模型
CatBoost回歸

- 使用時機:原生支持類別特徵,不需額外處理編碼
- 用戶 ID、地區、商品類別等,分類型的特徵CatBoost特別適合
使用CatBoost模擬房價預測:
實作範例程式碼📖
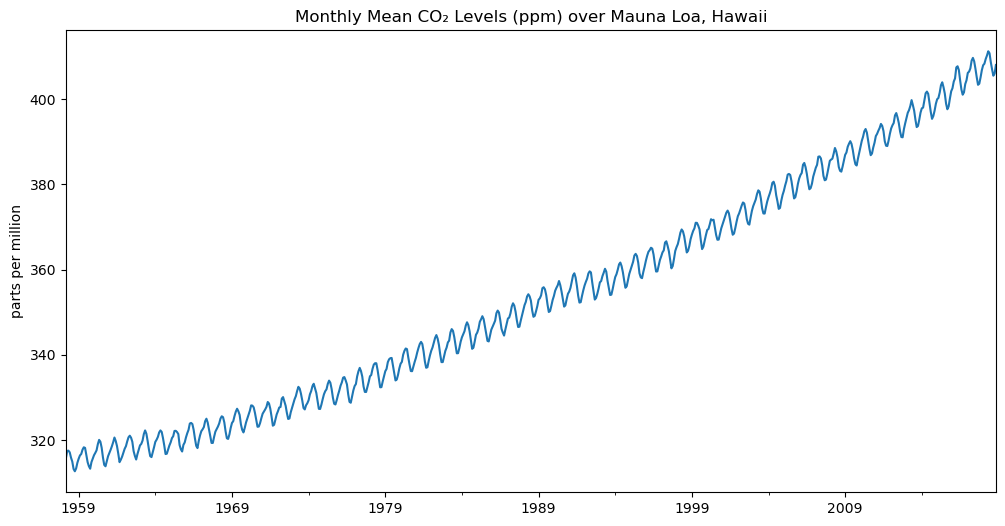
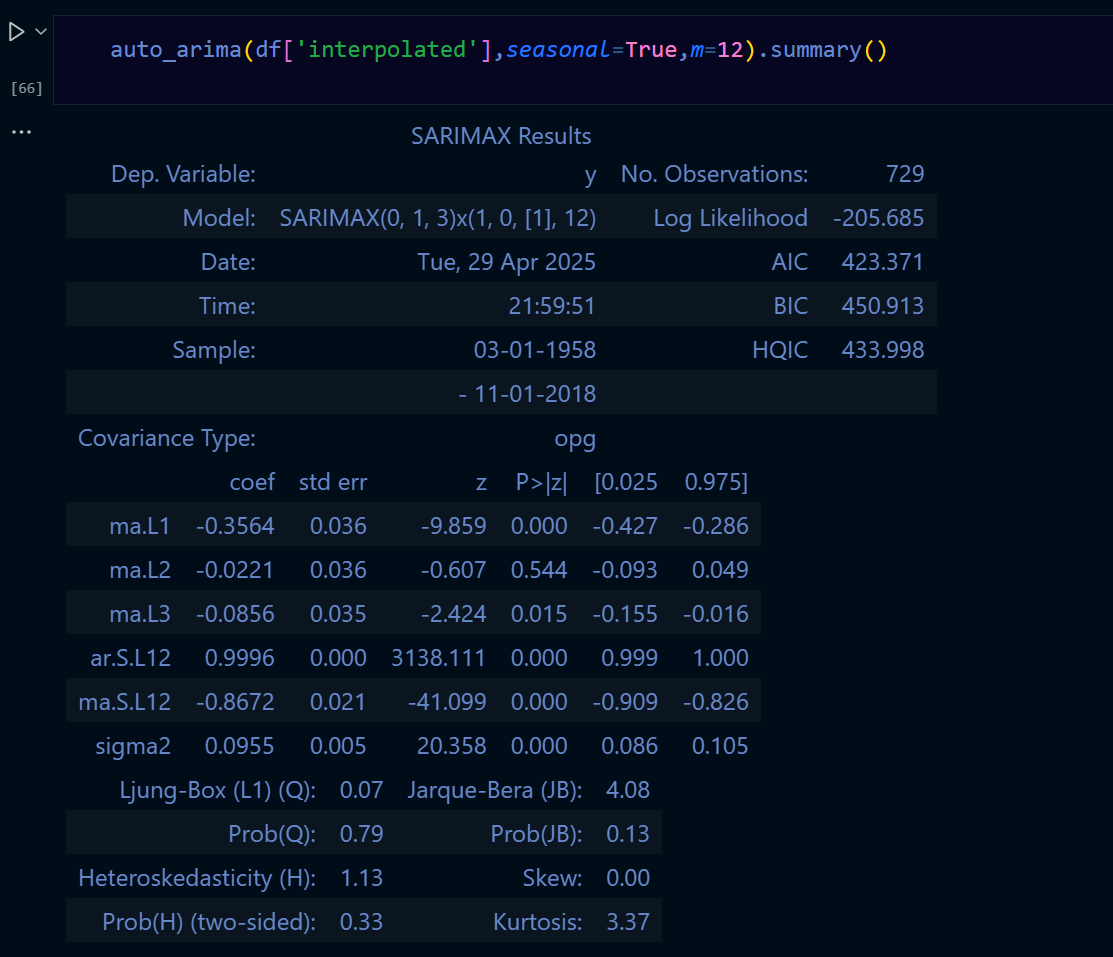
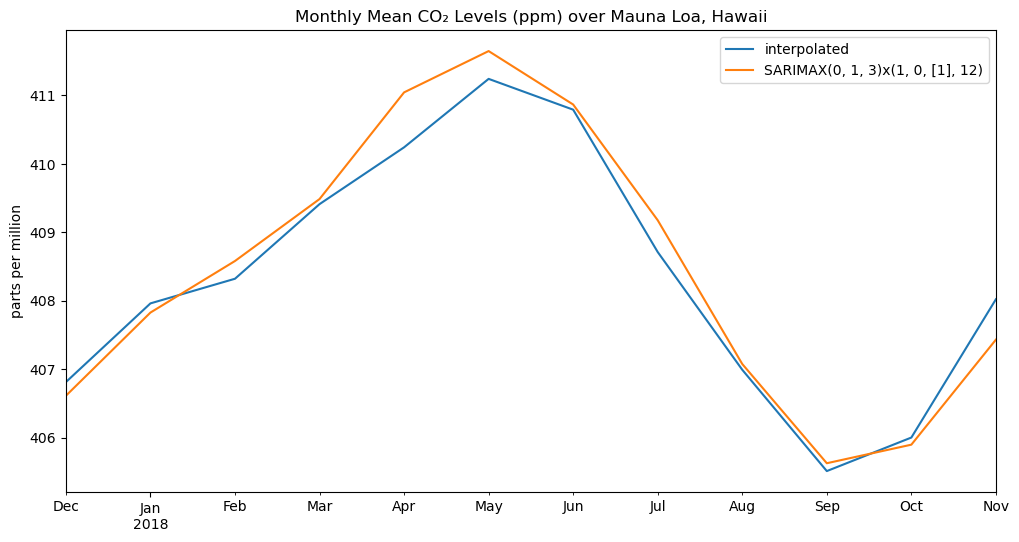
SARIMA季節性自迴歸整合移動平均模型
分類模型實作應用
LogisticRegression模型
KNeighborsClassifier模型
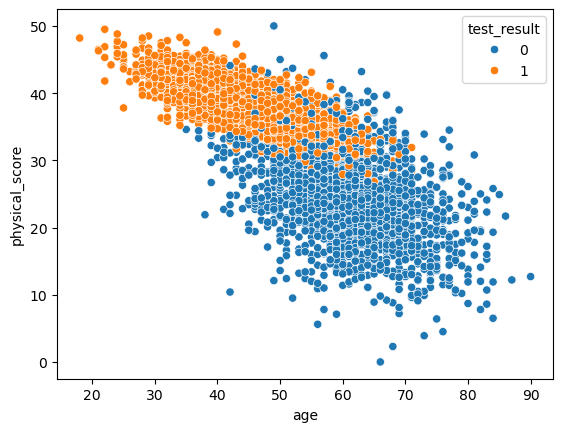
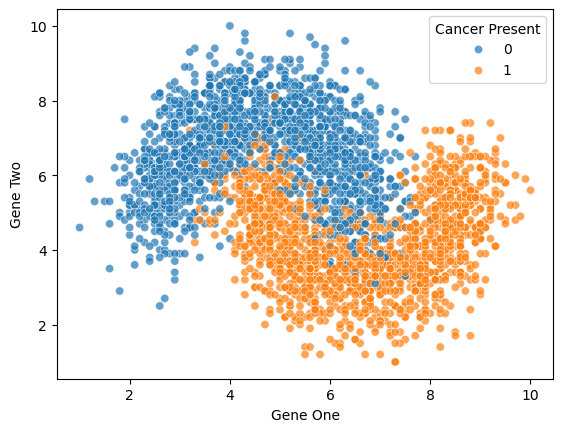
預測癌症發生
超參數:n_neighbors、weights、algorithm
使用時機:資料量小、特徵維度低
資料:非線性資料
特徵:基因1、基因2
標籤:發生/不發生
評估:accuracy_score、F1 score
RandomForest模型
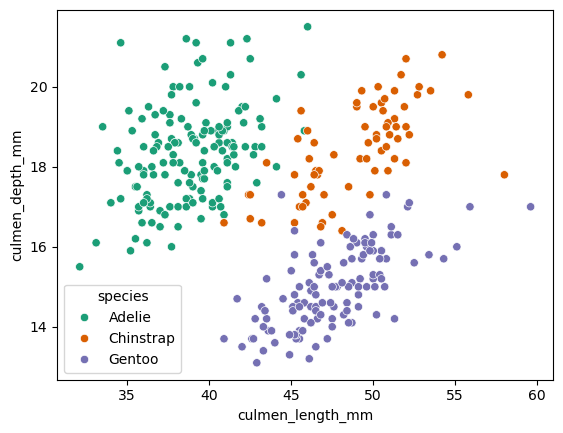
預測企鵝物種
超參數:n_estimators、max_depth、min_samples_split
使用時機:資料量大、特徵維度高
資料:非線性資料
特徵:嘴峰長度、嘴峰深度、鰭長度
標籤:企鵝種類
評估:accuracy_score、F1 score
決策樹的應用場景與隨機森林類似,但隨機森林通常能提供更好的性能和穩定性。
通常應用上都會優先使用隨機森林模型進行分析。
SVM模型
支持向量機
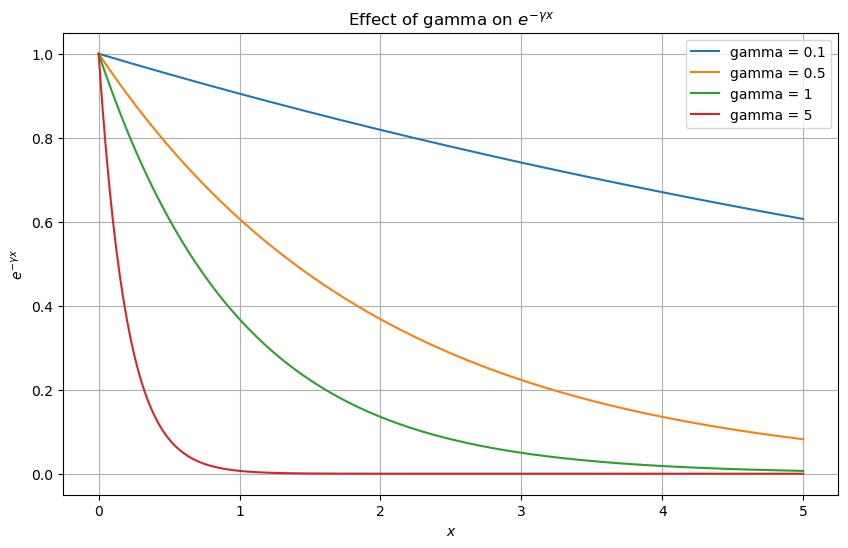
超參數:C、kernel、gamma
資料:非線性資料
模型選擇:線性、RBF、Polynomial
應用時機:資料難以分離、需要高維度特徵。
評估:分類 accuracy_score、F1 score
下圖展示了不同超參數下的模型效果:
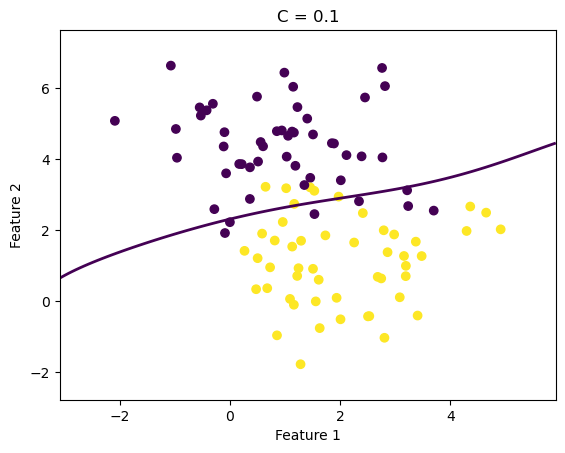
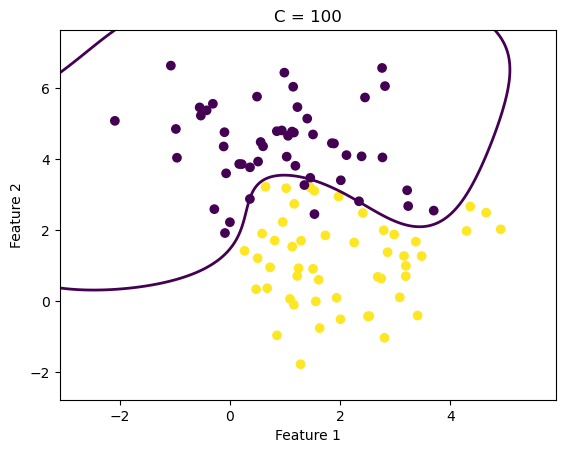
醫學研究中預測疾病是否發生
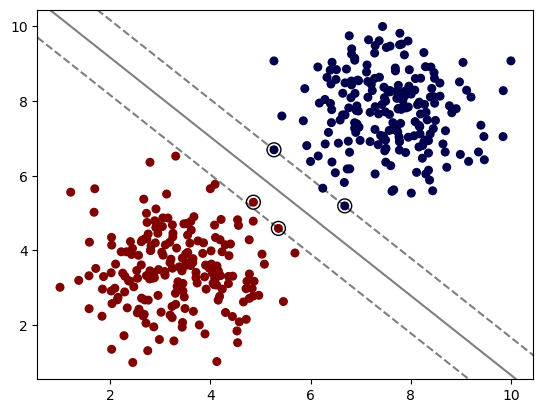
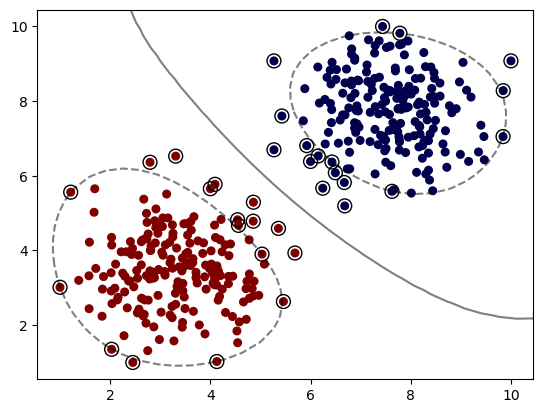
以下展示了不同核函數下的模型效果:
SVC Linear Kernel:
SVC RBF Kernel:
XGBClassifier模型
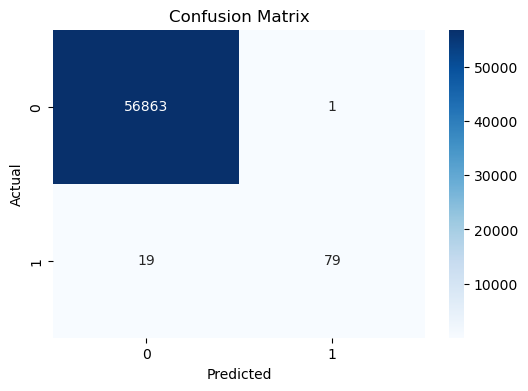
預測信用卡詐騙
超參數:learning_rate、n_estimators、max_depth
使用時機:資料量大、特徵維度高
資料:大資料量28萬筆
特徵:V1~V28 (28種特徵,已編碼)
標籤:是/否 (0/1)
評估:accuracy_score、F1 score
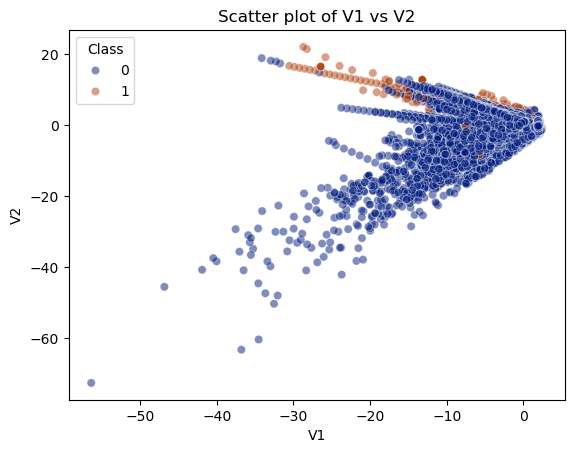
LightGBM模型
CatBoost模型
MultinomialNB模型