聚類模型實作應用
Kmeans模型
原理:K-means 是一種無監督學習算法,用於將數據點分成 K 個簇。它通過迭代地將數據點分配到最近的簇中心,然後更新簇中心來最小化簇內的距離。
超參數:K(簇的數量)。
使用時機:當數據集具有明顯的簇結構時,K-means 是一個有效的選擇。
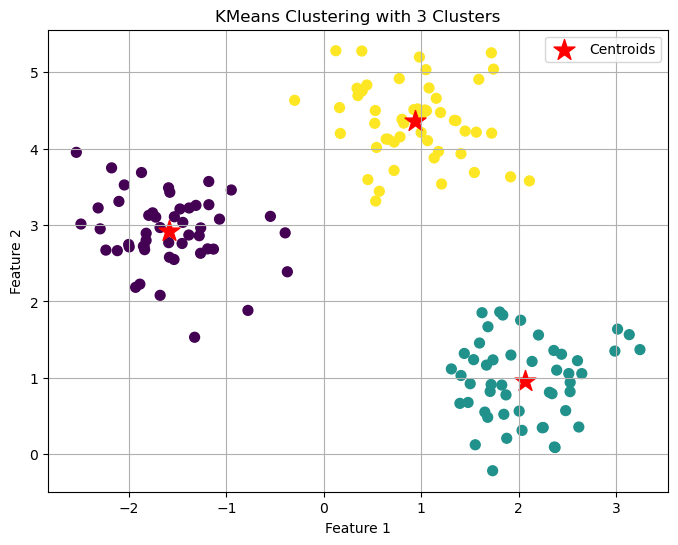
下圖展示了 K-means 的工作原理,2個特徵的資料指定n_clusters為3簇:
優點:簡單易用,計算效率高,適用於大型數據集。
缺點:需要預先指定 K 的值,對初始簇中心敏感,對噪聲和異常值敏感。
注意事項:K-means 假設簇是凸形的,並且簇的大小和密度相似,因此在處理非凸形或大小差異較大的簇時可能效果不佳。
應用:K-means 可用於市場細分、圖像壓縮、社交網絡分析等。在藥物研發中,K-means 可用於分析化合物的結構特徵,從而幫助識別潛在的藥物候選者。
評估:K-means 的性能通常通過輪廓係數(Silhouette Coefficient)或 Davies-Bouldin 指數來評估,這些指標衡量簇的緊密度和分離度。
使用時要指定k的數量,這可以通過繪製肘部圖(Elbow Method)來確定最佳的 K 值。
超參數:K(簇的數量)。
使用時機:當數據集具有明顯的簇結構時,K-means 是一個有效的選擇。
下圖展示了 K-means 的工作原理,2個特徵的資料指定n_clusters為3簇:
優點:簡單易用,計算效率高,適用於大型數據集。
缺點:需要預先指定 K 的值,對初始簇中心敏感,對噪聲和異常值敏感。
注意事項:K-means 假設簇是凸形的,並且簇的大小和密度相似,因此在處理非凸形或大小差異較大的簇時可能效果不佳。
應用:K-means 可用於市場細分、圖像壓縮、社交網絡分析等。在藥物研發中,K-means 可用於分析化合物的結構特徵,從而幫助識別潛在的藥物候選者。
評估:K-means 的性能通常通過輪廓係數(Silhouette Coefficient)或 Davies-Bouldin 指數來評估,這些指標衡量簇的緊密度和分離度。
使用時要指定k的數量,這可以通過繪製肘部圖(Elbow Method)來確定最佳的 K 值。
DBSCAN模型
原理:DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一種基於密度的聚類算法。它通過尋找高密度區域來識別簇,並將低密度區域視為噪聲。
超參數:eps(鄰域半徑)和 min_samples(形成簇所需的最小樣本數)。
應用:DBSCAN 可用於地理數據分析、異常檢測、圖像分割等。同Kmeans在藥物研發中,DBSCAN 可用於分析化合物的結構特徵,從而幫助識別潛在的藥物候選者。
評估:DBSCAN 的性能通常通過輪廓係數(Silhouette Coefficient)或 Davies-Bouldin 指數來評估,這些指標衡量簇的緊密度和分離度。
使用時要找出最佳的eps和min_samples參數,這可以通過繪製 K-dist 圖來實現。
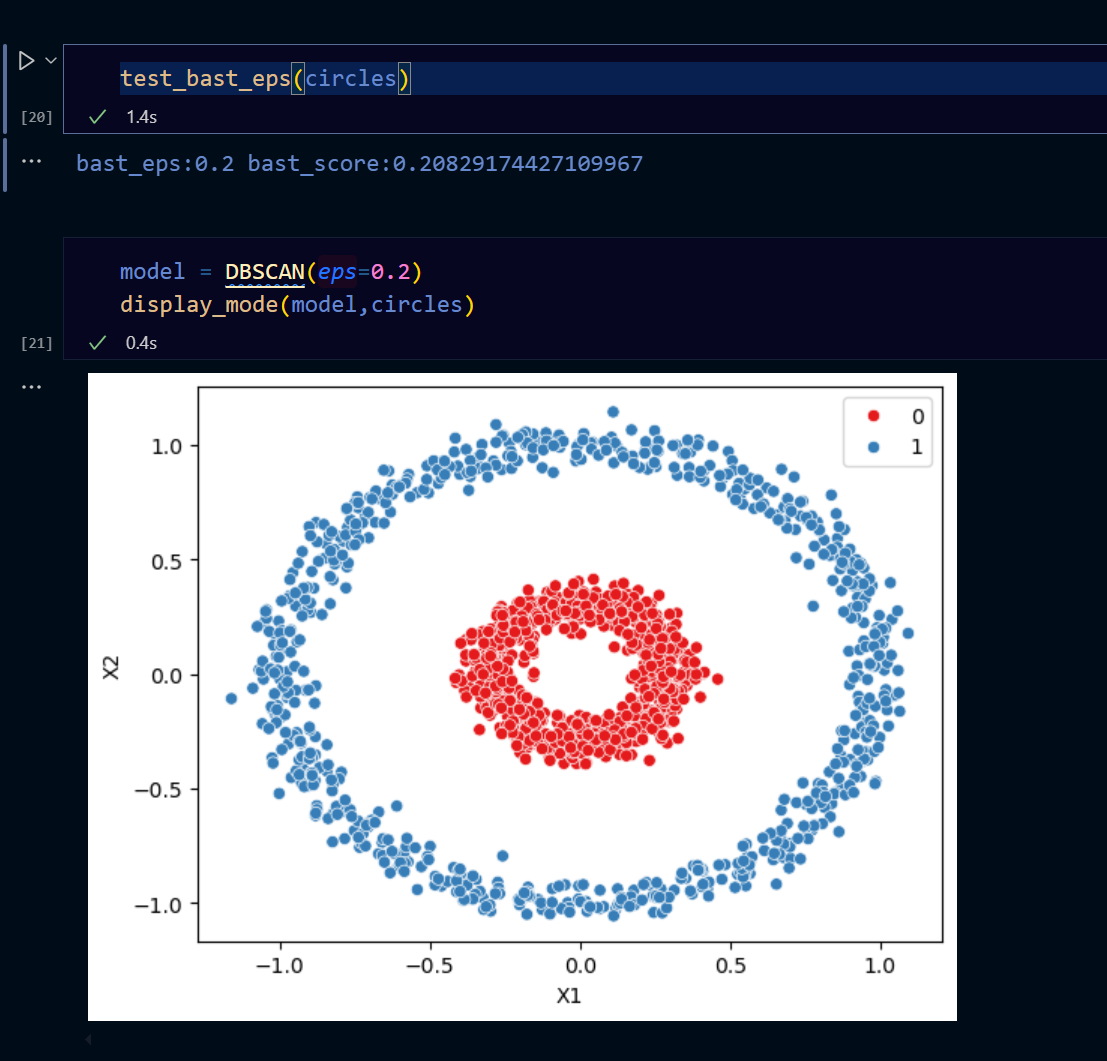
下圖展示了 DBSCAN 的工作原理,2個特徵的資料指定eps為0.2:
超參數:eps(鄰域半徑)和 min_samples(形成簇所需的最小樣本數)。
應用:DBSCAN 可用於地理數據分析、異常檢測、圖像分割等。同Kmeans在藥物研發中,DBSCAN 可用於分析化合物的結構特徵,從而幫助識別潛在的藥物候選者。
評估:DBSCAN 的性能通常通過輪廓係數(Silhouette Coefficient)或 Davies-Bouldin 指數來評估,這些指標衡量簇的緊密度和分離度。
使用時要找出最佳的eps和min_samples參數,這可以通過繪製 K-dist 圖來實現。
下圖展示了 DBSCAN 的工作原理,2個特徵的資料指定eps為0.2:
半監督學習實作應用
SelfTrainingClassifier
原理:SelfTrainingClassifier 是一種半監督學習方法,它首先使用標記數據訓練一個初始模型,然後使用該模型對未標記數據進行預測,並將高置信度的預測結果作為新的標記數據進行再訓練。
應用:SelfTrainingClassifier 可用於文本分類、圖像分類等任務,特別是在標記數據稀缺的情況下。
應用:SelfTrainingClassifier 可用於文本分類、圖像分類等任務,特別是在標記數據稀缺的情況下。
LabelSpreading
原理:LabelSpreading 是一種基於圖的半監督學習方法,它通過構建一個圖來表示數據點之間的關係,然後在圖上進行標籤傳播。
應用:LabelSpreading 可用於文本分類、圖像分類等任務,特別是在標記數據稀缺的情況下。 可先使用SelfTrainingClassifier再使用LabelSpreading進行標籤傳播,這樣可以更好地利用未標記數據。
應用:LabelSpreading 可用於文本分類、圖像分類等任務,特別是在標記數據稀缺的情況下。 可先使用SelfTrainingClassifier再使用LabelSpreading進行標籤傳播,這樣可以更好地利用未標記數據。