監督式學習模型評估方法
回歸模型評估
均方誤差 MSE:預測值與實際值之間差異的平方的平均值,數值越小表示模型越好
範例程式碼:
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_train, y_pred)
範例程式碼:
rmse = mean_squared_error(y_train, y_pred, squared=False)
範例程式碼:
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_train, y_pred)
範例程式碼:
from sklearn.metrics import r2_score
r2 = r2_score(y_train, y_pred)
範例程式碼:
mape = np.mean(np.abs((y_train - y_pred) / y_train)) * 100
範例程式碼:
from sklearn.metrics import r2_score
r2 = r2_score(y_train, y_pred)
分類模型評估
準確率 Accuracy:正確預測的樣本數佔總樣本數的比例,數值越大表示模型越好
精確率 Precision:正確預測的正樣本數佔所有預測為正樣本的比例,數值越大表示模型越好
召回率 Recall:正確預測的正樣本數佔所有實際正樣本的比例,數值越大表示模型越好
F1 分數 F1 Score:精確率和召回率的調和平均數,數值越大表示模型越好
特異度 Specificity:正確預測的負樣本數佔所有實際負樣本的比例,數值越大表示模型越好
精確率 Precision:正確預測的正樣本數佔所有預測為正樣本的比例,數值越大表示模型越好
召回率 Recall:正確預測的正樣本數佔所有實際正樣本的比例,數值越大表示模型越好
F1 分數 F1 Score:精確率和召回率的調和平均數,數值越大表示模型越好
範例程式碼:
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
print(classification_report(y_train, y_pred))
sns.heatmap(confusion_matrix(y_test, y_pred),
annot = True,
fmt = 'd',
cmap = 'Blues',
xticklabels = ['Negative', 'Positive'],
yticklabels = ['Negative', 'Positive']
)
範例程式碼:
from sklearn.metrics import roc_curve, auc
fpr, tpr, _ = roc_curve(y_train, y_score)
roc_auc = auc(fpr, tpr)
特異度 Specificity:正確預測的負樣本數佔所有實際負樣本的比例,數值越大表示模型越好
模型評估視覺化
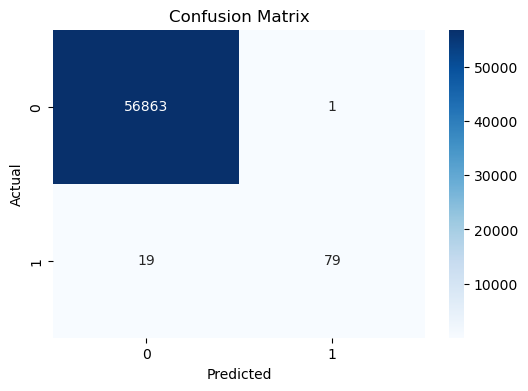
混淆矩陣 Confusion Matrix - 常用於評估分類模型性能
下圖為XGBoost模型在信用卡詐騙數據集上的混淆矩陣示例:
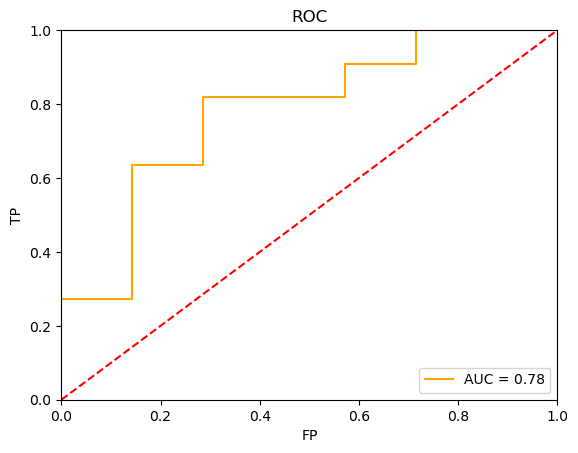
ROC 曲線 ROC Curve - 常用來評估二元分類模型性能,ROC曲線下面積(AUC)越大,表示分類器的性能越好,將正樣本排在負樣本之前的概率越高
下圖為二元分類模型在數據集上的ROC曲線示例:
學習曲線 Learning Curve - 常用來評估模型在不同訓練集大小下的性能變化
以Iris數據集為例,使用學習曲線來評估LogisticRegression模型的過擬合情況。可以使用 learning_curve 函數來生成學習曲線,並使用 train_test_split 將數據分成訓練集和驗證集。
下圖是學習率理想情況的學習曲線示例:
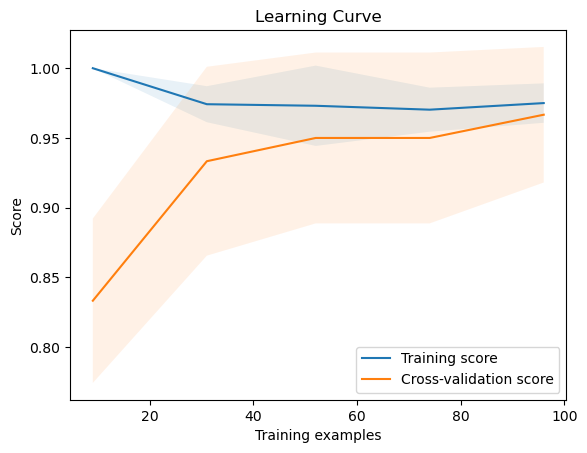
在這個例子中,訓練集和驗證集的評分都很高,並且隨著訓練集大小的增加,兩條曲線趨於平穩且接近。這表示模型具有良好的泛化能力。
過擬合評估:使用訓練集和驗證集的性能差異來判斷模型是否過擬合,通常會使用學習曲線來輔助判斷。
PR 曲線 Precision-Recall Curve - 常用來評估不平衡數據集的分類模型性能
特徵重要性 Feature Importance
下圖為XGBoost模型在信用卡詐騙數據集上的混淆矩陣示例:
ROC 曲線 ROC Curve - 常用來評估二元分類模型性能,ROC曲線下面積(AUC)越大,表示分類器的性能越好,將正樣本排在負樣本之前的概率越高
下圖為二元分類模型在數據集上的ROC曲線示例:
學習曲線 Learning Curve - 常用來評估模型在不同訓練集大小下的性能變化
以Iris數據集為例,使用學習曲線來評估LogisticRegression模型的過擬合情況。可以使用 learning_curve 函數來生成學習曲線,並使用 train_test_split 將數據分成訓練集和驗證集。
下圖是學習率理想情況的學習曲線示例:
在這個例子中,訓練集和驗證集的評分都很高,並且隨著訓練集大小的增加,兩條曲線趨於平穩且接近。這表示模型具有良好的泛化能力。
範例程式碼:
import numpy as np
from sklearn.model_selection import learning_curve
train_sizes, train_scores, test_scores = learning_curve(
estimator=model,
X=X_train,
y=y_train,
train_sizes=np.linspace(0.1, 1.0, 5),
cv=5,
scoring='accuracy',
n_jobs=-1,
shuffle=True,
random_state=42
)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
# 繪製學習曲線
plt.plot(train_sizes, train_mean, label='Training score')
plt.fill_between(train_sizes, train_mean - train_std, train_mean + train_std, alpha=0.1)
plt.plot(train_sizes, test_mean, label='Cross-validation score')
plt.fill_between(train_sizes, test_mean - test_std, test_mean + test_std, alpha=0.1)
plt.xlabel('Training examples')
plt.ylabel('Score')
plt.title('Learning Curve')
plt.legend(loc="best")
plt.show()
過擬合評估:使用訓練集和驗證集的性能差異來判斷模型是否過擬合,通常會使用學習曲線來輔助判斷。
- 學習率理想情況:訓練集和驗證集的評分都高,並且隨著訓練集大小的增加,兩條曲線趨於平穩且接近。這表示模型具有良好的泛化能力
- 過擬合情況:訓練集評分很高,但驗證集評分很低,且兩條曲線之間差距很大。這表示模型過於複雜,在訓練數據上表現良好,但在新數據上表現不佳
- 欠擬合情況:訓練集和驗證集評分都很低,且兩條曲線都遠低於1.0 (或你使用的其他指標的最大值)。 這表示模型太簡單,無法捕捉數據中的模式
PR 曲線 Precision-Recall Curve - 常用來評估不平衡數據集的分類模型性能
特徵重要性 Feature Importance
非監督式學習模型評估方法
聚類模型評估
輪廓係數 Silhouette Coefficient:衡量聚類效果的指標,值介於 -1 到 1 之間,越接近 1 表示聚類效果越好
Calinski-Harabasz 指數:衡量聚類效果的指標,值越大表示聚類效果越好
Davies-Bouldin 指數:衡量聚類效果的指標,值越小表示聚類效果越好
聚類內距離 Intra-cluster Distance:同一聚類內樣本的距離
聚類間距離 Inter-cluster Distance:不同聚類間樣本的距離
Calinski-Harabasz 指數:衡量聚類效果的指標,值越大表示聚類效果越好
Davies-Bouldin 指數:衡量聚類效果的指標,值越小表示聚類效果越好
聚類內距離 Intra-cluster Distance:同一聚類內樣本的距離
聚類間距離 Inter-cluster Distance:不同聚類間樣本的距離
降維模型評估
- 重建誤差 Reconstruction Error
- 可視化效果 Visualization Effectiveness
- 特徵保留率 Feature Retention Rate
- 主成分解釋變異量 Explained Variance Ratio
交叉驗證
Cross-Validation
- K-fold Cross-Validation:將數據集分成 K 個子集,輪流用其中一個子集作為驗證集,其餘作為訓練集,用以評估模型在未見過資料上的泛化能力 (generalization ability),可幫助我們判斷資料集是否「適合」用於訓練模型
- Stratified K-fold Cross-Validation:在 K-fold 中保持每個類別的比例
- Leave-One-Out Cross-Validation (LOOCV):每次只留一個樣本作為驗證集,其餘作為訓練集
- Time Series Cross-Validation:考慮時間序列的順序,進行訓練和驗證
- cross_val_score - 用於評估模型性能的函數
- GridSearchCV - 用於超參數調整的交叉驗證方法
- RandomizedSearchCV - 用於隨機超參數調整的交叉驗證方法
- 評估指標:accuracy、precision、recall、f1-score 等
K-fold Cross-Validation
詢找並評估最佳超參數
調參工作流與評分
比較評估 LogisticRegression、DecisionTreeClassifier、RandomForestClassifier、svm 模型資料集分析的適用性方法建立
實作範例程式碼📖